
Geschrieben von
René Elgersma
Jan 2025
Wer regelmäßig Power BI Reports betreut, kennt die Herausforderung: Nach dem Deployment trudeln diverse Änderungswünsche ein. Von kleinen kosmetischen Anpassungen wie „Visual Y auf Seite X bitte drei Pixel breiter“ bis hin zu komplexeren Anforderungen wie dem Austausch von Measures in mehreren Visuals – das Management solcher Aufgaben kann schnell zeitaufwendig und unübersichtlich werden. Doch es gibt Wege, die Arbeit zu erleichtern und effizienter zu gestalten.
In diesem Beitrag zeige ich, wie man Power BI Reports optimal verwaltet und Automatisierungspotenziale nutzt, um Änderungen schneller umzusetzen – ohne stundenlang in Power BI Desktop zu klicken.
Das richtige Speicherformat: Enhanced Metadata Format (PBIR)
Eine der ersten Stellschrauben für ein effizientes Report-Management ist das Speicherformat. Beim Entwickeln eines Reports in Power BI Desktop kann zwischen verschiedenen Formaten gewählt werden. Für eine Integration mit Source Control – wie Git – empfiehlt sich das Speichern als Power BI Project (pbip).
Darüber hinaus gibt es das „Enhanced Metadata Format“ (PBIR), das eine strukturiertere Dateiverwaltung ermöglicht.
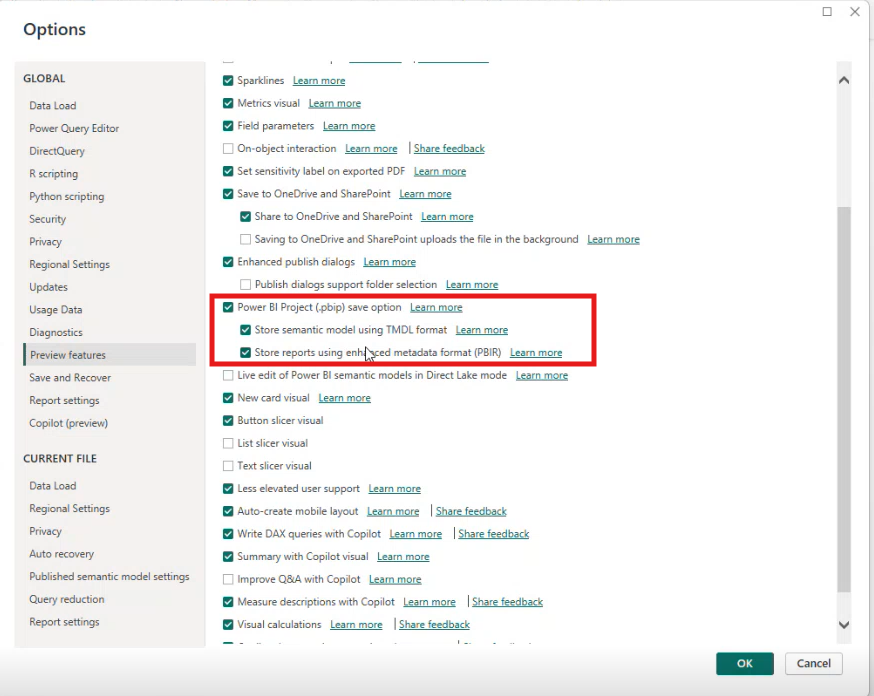
Aktiviert man diese Option, wird der Report nicht nur als einzelne Datei gespeichert, sondern ein Ordner erstellt mit den Namen „REPORTNAME.Report“.
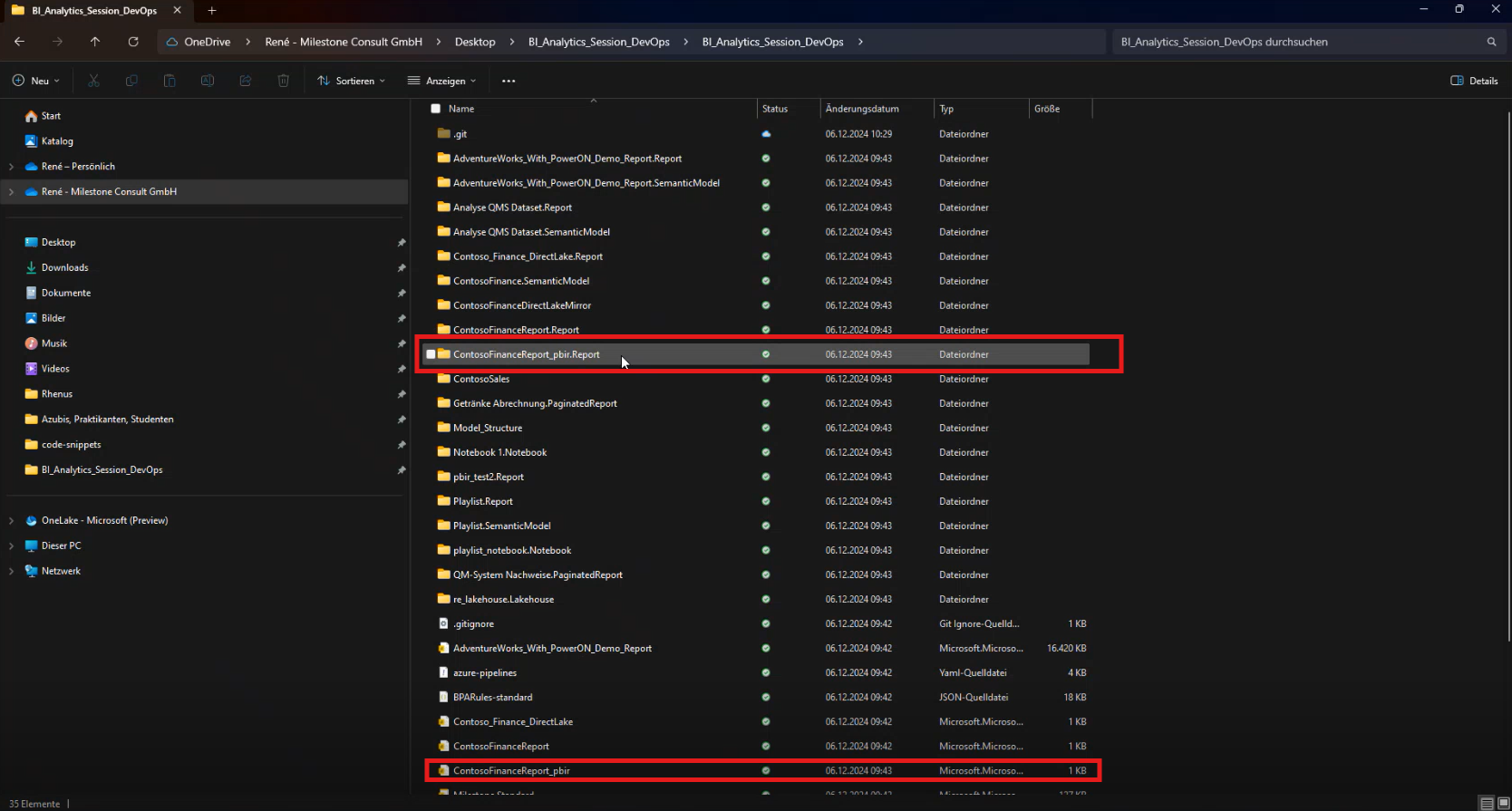
In diesem Ordner befinden sich in Unterverzeichnissen zunächst der Unterordner „pages“, wo jede Page mit ihrer ID als eigener Ordner aufgeführt wird. In diesen Ordnern befinden sich wieder jeweils in Ordnern die jeweiligen Visuals, die auf dieser Page sind. In den Visual Ordnern widerrum befindet sich eine json Datei, die dann das Visual beschreibt.

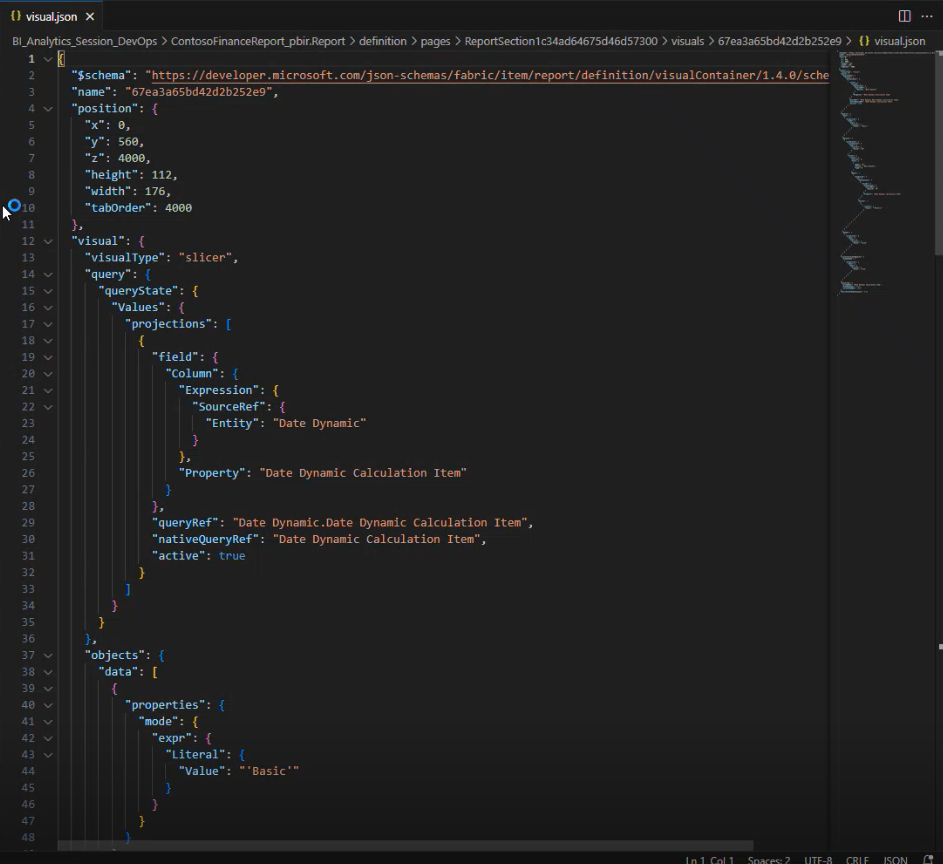
Das bietet klare Vorteile:
- Jede Seite (Page) und jedes Visual hat eine eigene Datei.
- Informationen wie Position, Größe und Typ eines Visuals sind leicht über die viusal.json zugänglich.
- Die Dateistruktur erleichtert Änderungen direkt im Code – ohne Power BI Desktop zu öffnen.
Beispiel:
Möchte man die Reihenfolge der Seiten im Report ändern, kann dies direkt über die page.json erfolgen.
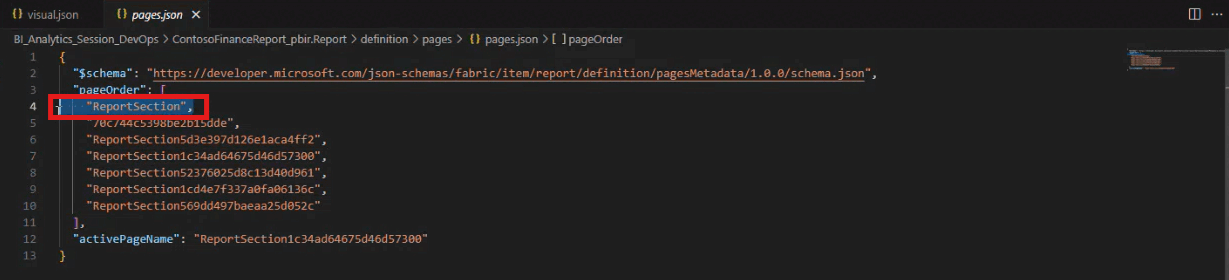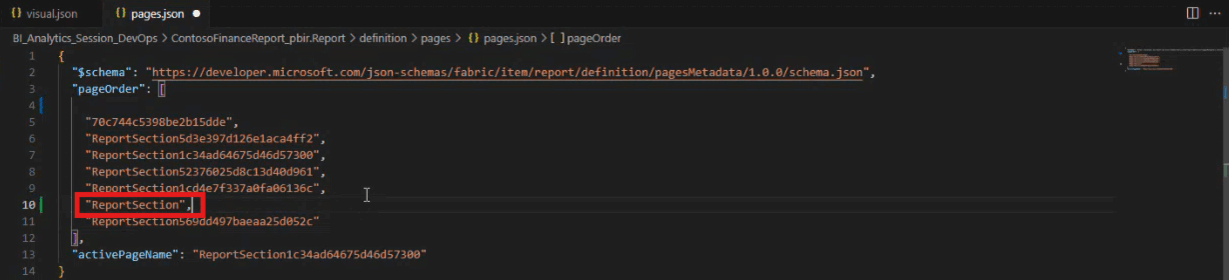
Änderungen wie die Breite eines Visuals lassen sich über die zugehörige visual.json vornehmen. Mit einem simplen Commit und Push in das verbundene Git-Repository werden die Änderungen synchronisiert und können im Power BI Service aktualisiert werden:
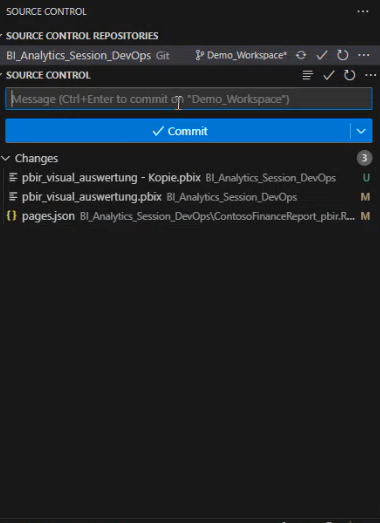
Automatisierte Visual-Identifikation
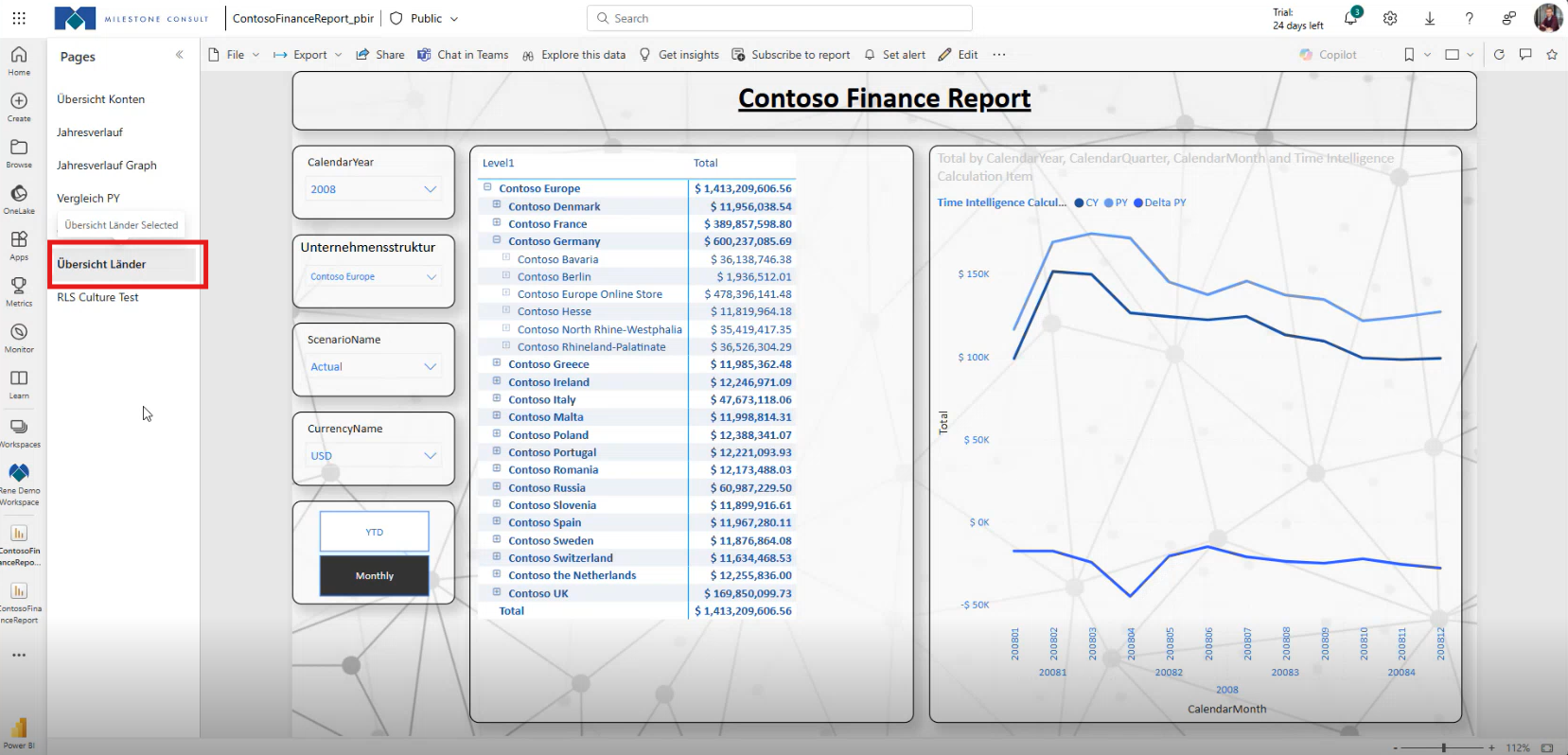
Die Strukturierung im PBIR-Format bringt Ordnung, doch bei umfangreichen Reports mit dutzenden Seiten und hunderten Visuals wird die Verwaltung dennoch unübersichtlich. Welche Visual-ID gehört zu welchem Element? Um dieses Problem zu lösen, habe ich mit meinem Kollegen Philipp Lehmann einen Prozess entwickelt, damit man die Übersicht behält und am Ende in einem Power BI Report das hier bekommt:

- Übersicht: Alle Visuals auf einer ausgewählten Seite eines Reports werden mit ihrer ID und ihrem Titel dargestellt, wenn einem Visual beim Erstellen ein Titel zugewiesen wurde. Der Titel kann für interne Zwecke genutzt und später ausgeblendet werden, sodass er für die Nutzer unsichtbar bleibt, aber weiterhin verfügbar ist. Dies erleichtert die Verwaltung und Identifikation von Visuals im Report.
- Visual-Details: Für jede Seite werden die Visuals aufgelistet, inklusive Typ (z. B. Slicer, Line Chart)
- Direktlinks: Per Klick auf ein Visual wird man direkt in das entsprechende Repository im DevOps geleitet
Beispiel: Angenommen, man möchte das Line Chart auf der Seite „Jahresverlauf“ anpassen. Mit einem Klick öffnet sich die entsprechende JSON-Datei im Repository:
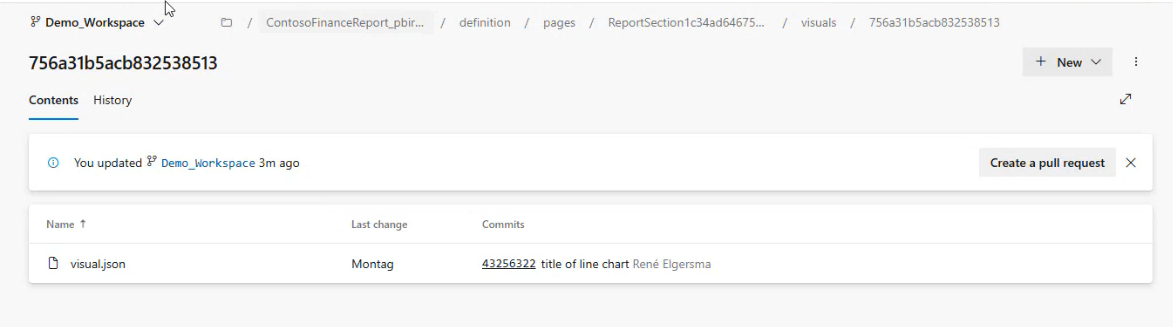
Hier kann direkt die gewünschte Anpassung – z. B. eine Änderung der Visual-Größe – vorgenommen werden.

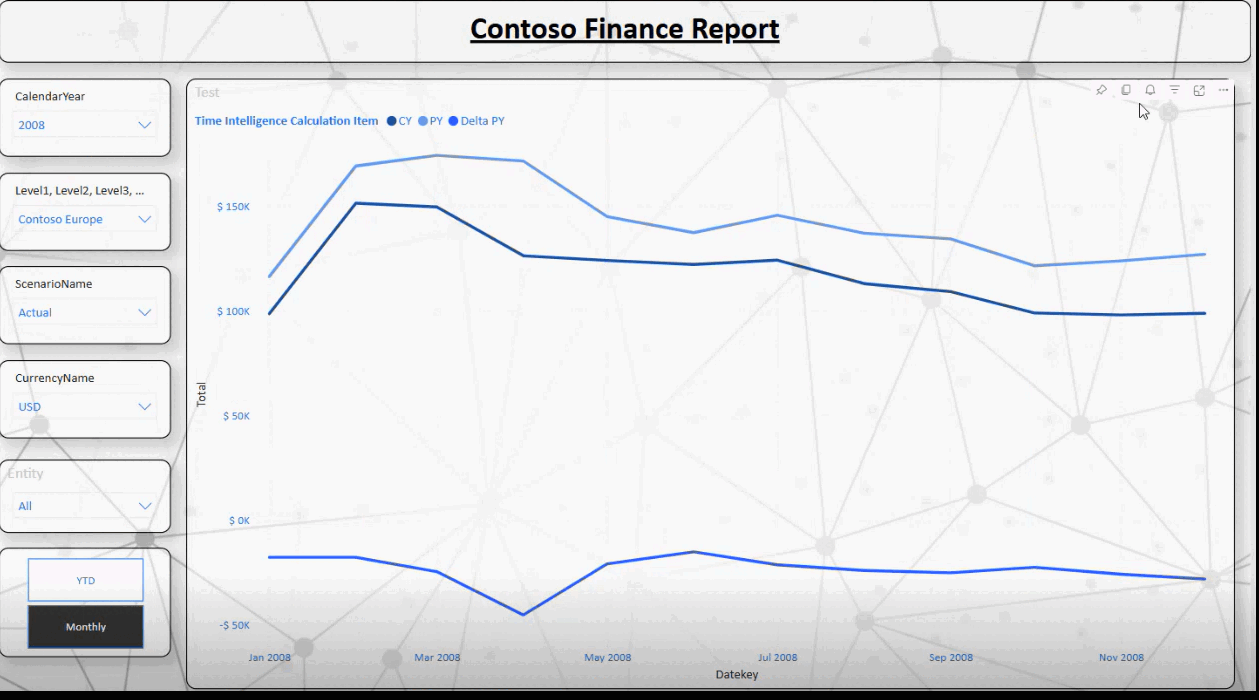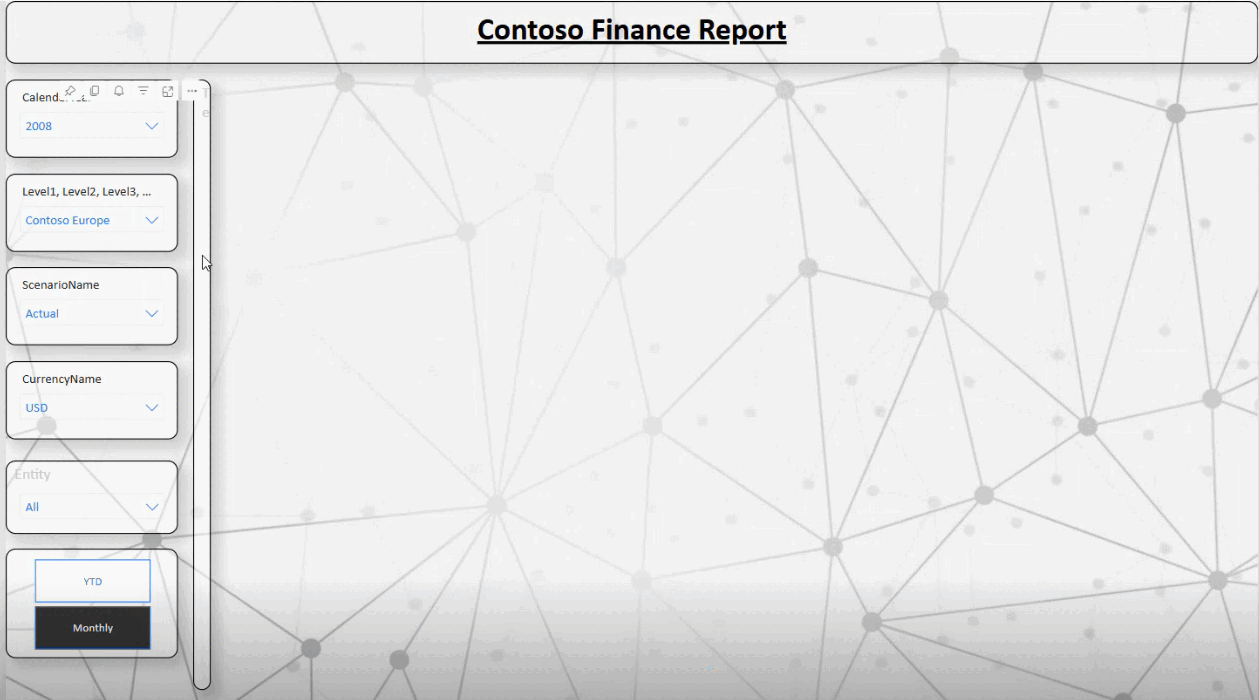
Nach dem Update sieht man die Änderungen sofort im Report.
Umsetzung mit Power Query und JSON
Der Ansatz basiert auf der Verarbeitung der Ordnerstruktur des PBIR-Formats mithilfe von Power Query. Dabei durchläuft es mehrere wichtige Schritte:
- Daten einlesen: Power Query analysiert die Ordnerstruktur des PBIR-Formats und liest relevante Dateien wie visual.json und page.json ein. Diese Dateien enthalten die Metadaten des Reports, die für die Verwaltung entscheidend sind.
- Metadaten extrahieren: Aus den JSON-Dateien werden die IDs der Pages und Visuals sowie weitere Eigenschaften wie Titel, Typ, Größe und Position der Visuals extrahiert. Diese Informationen bilden die Grundlage für eine strukturierte und übersichtliche Darstellung.
- Transformation: Die extrahierten Informationen werden mithilfe von Power Query in eine nutzerfreundliche Struktur gebracht. Dazu gehört:
- Erweiterung der Metadaten: Verschachtelte Eigenschaften, wie der Titel eines Visuals, werden aufgelöst und in einer leicht zugänglichen Form dargestellt.
- Erstellung von Links: Alle relevanten Elemente, wie Pages und Visuals, werden mit Links versehen, die direkt in die Cloud-Umgebung (z. B. DevOps) führen. Dadurch können Änderungen unmittelbar an der richtigen Stelle vorgenommen werden.
Ein zentraler Punkt war die Handhabung der tief verschachtelten JSON-Daten. Um wichtige Eigenschaften wie den Titel eines Visuals zugänglich zu machen, mussten mehrere Transformationen vorgenommen werden. Power Query ermöglichte es, die verschiedenen Ebenen der JSON-Daten systematisch zu durchsuchen und die benötigten Informationen zu extrahieren. Darüber hinaus wurden die generierten Links so angepasst, dass sie direkt auf das entsprechende Repository in der DevOps-Umgebung zeigen. Diese Anpassung erhöht die Effizienz, da Änderungen nicht mehr lokal durchgeführt und hochgeladen werden müssen, sondern direkt in der Cloud erfolgen können.
Fazit
Die bisherige Lösung stellt einen interessanten Ansatz dar, um Übersicht und Struktur in Power BI Reports zu schaffen. Durch die Automatisierung mit Power Query konnten wichtige Metadaten aus dem PBIR-Format effizient extrahiert und verarbeitet werden. Besonders hervorzuheben ist die Möglichkeit, tief verschachtelte JSON-Eigenschaften wie Visual-Titel zugänglich zu machen und Links direkt auf die Cloud-Umgebung zu verweisen.
Diese Methode bietet zudem Potenzial für Erweiterungen, etwa die Anwendung auf Measures oder das direkte Bearbeiten von JSON-Dateien über Search-and-Replace. Eine weitere Ausbaustufe wäre die Entwicklung eines Templates, das die Automatisierung und Wiederverwendbarkeit noch weiter verbessert. Wichtig ist jedoch, dass die hier vorgestellte Herangehensweise nur sinnvoll ist, wenn ein Repository zur Versionierung und Verwaltung genutzt wird.

Über den Autor
René Elgersma arbeitet seit 2018 im Bereich Data Analytics bei Milestone Consult. In dieser Zeit hat er an verschiedenen BI-Projekten, unter anderem in der chemischen und pharmazeutischen Industrie mitgewirkt. Seine akademische Ausbildung umfasst einen Bachelor of Science in Mathematik mit einem Schwerpunkt auf Analysis und Differentialgeometrie.


